# 为什么会出现向量化执行引擎
# 制约数据库系统利用硬件能力的因素
- 查询执行模型:传统的数据库查询执行都是采用一次一 tuple 的 pipleline 执行模式。这样 CPU 的大部分处理时不是用来真正的处理数据,而是在遍历查询操作树,这样 CPU 的有效利用率不高。同时这也会导致低指令缓存性能和频繁跳转。且这种方式的执行,不能够利用到现在新硬件的新的能力来加速查询的执行。
- 存储:从存储层面上来看,磁盘读写能力的提升并没有 CPU 硬件计算能力提升的那么迅速,加上通常数据库在对于随机访问的支持,对于数据的存放位置没有做特殊的要求。目前对于磁盘来说,顺序读取的效率是比随机读取的效率要高的。但是通常数据库很多数据存储都更倾向(或者说在运行了一段时间以后)数据是处于随机存放的状态。
# 向量化执行引擎能够发挥效率的前提
要获得到向量化执行引擎的收益,是需要有一定的条件支持的:向量化执行引擎效率的发挥需要数据库能够提供列存储表的支持。
# 列存储是什么
说到列存储不得不说行存储,我们最先接触到的数据库系统,大部分都是行存储系统。
# 行存储
行存储以行的形式来组织数据。
[
{
"title": "Oriented Column Store",
"author": "Alex",
"publish_time": 1508423456,
"like_num": 1024
},{
"title": "Apache Druid",
"author": "Bob",
"publish_time": 1504423069,
"like_num": 10
},{
"title": "Algorithm",
"author": "Casey",
"publish_time": 1512523069,
"like_num": 16
}
]
行存储在磁盘的表现形式如下图

它利于数据一行一行的写入,写入一条数据记录时,只需要将数据追加到已有数据记录后面即可。
# 列存储
列式存储将每一列的数据组织在一起
还是上面的数据,列存储在磁盘的表现形式如下图

# 对比
现在有一需求,我们需要对 like_num 列做 sum 操作,假设磁盘一次读取只能读取 4 个方框对读取,则针对行存储我们需要 3 次磁盘 I/O 操作,而针对于列存储只需要1次磁盘 I/O 操作即可完成所需数据读取。
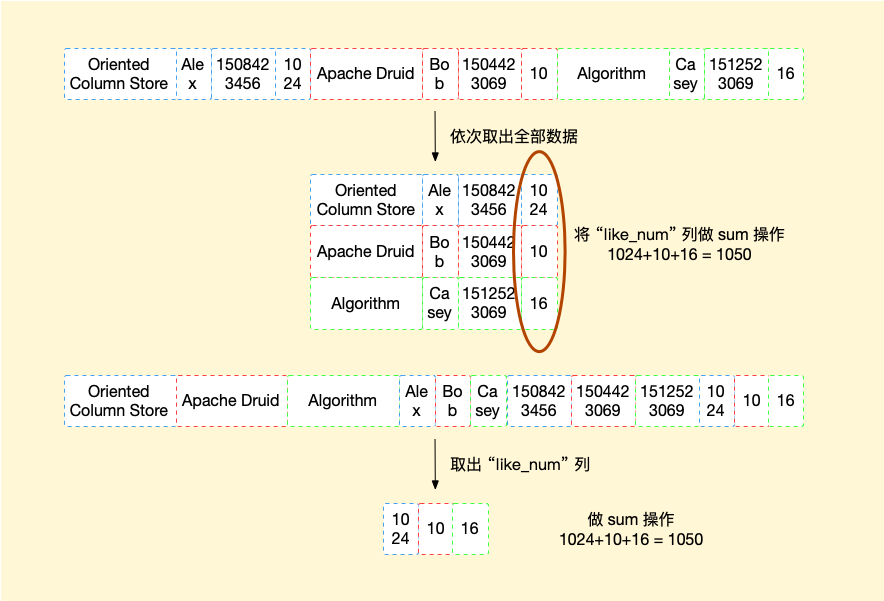
近年来,使用列存来实现存储的数据库这一技术成为大型分析型数据库越来越青睐的一种 OLAP 数据库的存储选型方案。 使用列存储技术有以下几点优势:
压缩能力的提升: 因为列存储技术在数据表的存储上使用数据表的列(记录的一个属性)为单位存储数据,这样类型一致的数据被放在一起,这样类似的数据在进行压缩的时候,能够达到一个比较好的压缩比。假设一家公司的客户表,其中有一列是省份,这一列大多数的值将是“江苏”、“杭州”或“广东”。这个列的值会存储在一起而不是分散到包含很多不相关的字符串和数字的其他列的值之间。在我们不做其他处理的情况下,与基于行的存储格式相比,对列存储格式进行压缩能够有更显著的压缩效果
减少I/O的读入总量: 因为列存按列为单位,这样,我们在读取数据的时候仅需要读入需要的列,相对于行存将所有数据读取上来再提取对应的属性,减少了I/O总量。
减少查询执行过程中的节点函数调用次数: 举个例子,如果当前列存的每次以一个数据块(segment,假设一个数据块包含某列1024行值)返回给上层节点的话,会极大的减少函数调用次数,达到提升查询执行性能的效果。
向量化执行: 因为列存每列的各行数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作,可以使用 SIMD 进一步提升计算效率,即便运算的机器上不支持 SIMD, 也可以通过一个循环来高效完成对这个数据块各个值的计算。
在程序的世界里,我们学会了,任何的选择和倾向都是有代价的。空间换时间,时间换空间,一致性可用性相互平衡等。选择列式存储必然也有不利的一面。首先就表现在数据写入上。
当一条新数据到来,需要将每一列存储到对应的位置。这样就需要多次写磁盘操作。而对于行存储来说,只需要一次写操作即可完成数据对写入操作。这也是列存储不适用于 OLTP 场景的主要原因。
# 向量化执行引擎
向量化处理已成为在现代硬件条件下构建高效分析查询引擎,进而加速数据处理的标准。这种模式需要按列表示的数据来编写高效优化的查询处理算法。向量化的过程和传统的基于 tuple 的查询过程模式有着显著区别。 两种方法最主要的不同是,前者是基于列而不是基于 tuple 来重写查询处理算法。连续存储的一列数据,在内存中可以表示为一个向量,这个向量包含了该列中固定数目的一些值。
向量模式和传统模式的第二个不同是,我们可以添加一个块,而不是在查询计划树顶部一次添加一个元组。一个块由固定的一组 tuple 组成,它代表一组向量,这些向量和列/字段有一一对应的关系。向量块是数据的基本单元,它经由执行计划树,从一个操作符流向另一个操作符。
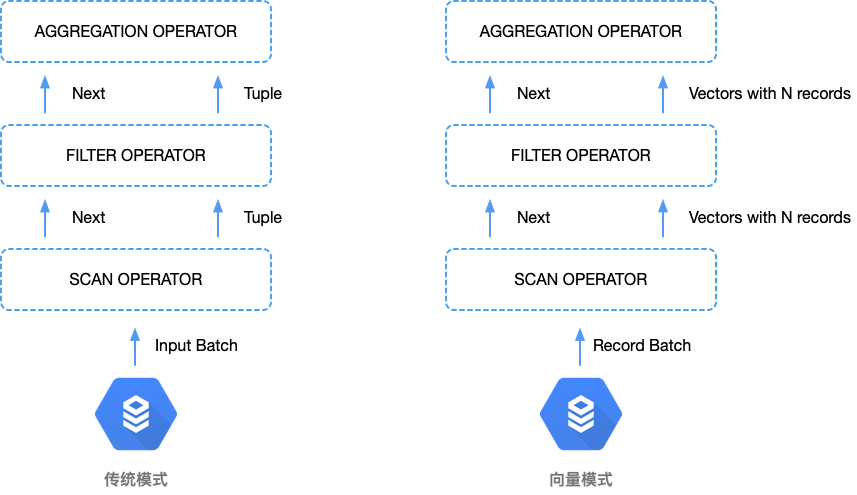
# 传统模型
左侧图为传统的一次操作一个 tuple 的处理流程。
- 扫描算子开始获取输入数据,并将数据传递给上层节点即过滤算子
- 过滤算子根据查询条件将符合条件的 tuple 继续向上传递给聚合算子
- 聚合算子继续处理记录(Aggregation 节点不是立刻往上层节点返回数据,它需要计算完所有的 tuple,才能继续往上层节点返回,所以这里聚合算子在处理好这个 tuple 之后,又会往下调用扫描算子返回下一条符合过滤条件的记录,在整个过程中需要聚合算子缓存中间结果)
算子不停调用查询计划树下层的下一个算子。其结果就是位于树下层的算子把 tuple 推向位于树顶的算子。这就是查询的执行过程。
由于有大量的函数调用,且每次函数调用时从一个运算符到另一个运算符需要处理或传输的数据不多,在这个执行过程中,性能开销很大。其次,当仅需要处理元组里列的一个子集时,需要传递整个 tuple。
# 向量模型
右侧为向量模型,执行逻辑基本上与左侧的传统模式一致,不同的是每次扫描处理是一个向量块。每个向量有一组记录或列值。在这个数据集合中,有多少列,就有多少向量。不断往查询计划树上面压入一批向量,它们就是查询计划中不同操作符的输入与输出。这样我们最为直观的观察就是从上层节点向下层节点的调用次数少了。相应的CPU的利用率也得到了提高。
向量化的代码可以充分利用 CPU 的缓存。例如,有 10 列的一行数据和只需操作一列的查询计划。在基于行的查询处理模式中,9 列数据会不必要的占用缓存,限制了可以进入缓存的数据数量。在基于列的处理中,只会读入感兴趣的列数据,这样可以一起处理更多的值,同时有效使用了 CPU 的内存带宽。
现代处理器有扩展的指令集,在单独的一个指令中,该指令集可以扩展向量执行概念到多列的值。单指令多数据流(SIMD)指令在 20 世纪 90 年代成为桌面运算主流,提高了多媒体应用如游戏的性能。
对多个值做相同改变,比如调整一个图像的亮度时,SIMD 尤其有用。每个像素点的亮度由红色(R),绿色(G)和蓝色(B)的值确定。改变亮度,要从内存读取 R,G 和 B 的值,并进行调整,调整后的值要重写回内存。不使用 SIMD,像素的 RGB 值会依次单个读入内存。使用 SIMD,像素的 RGB 数据块可以在一个指令中一起进行处理。这样就极大地提高了有效性。
这些概念在分析学的数据处理中非常适用。SIMD 采用和并发无关的数据级并行。SIMD 指令允许在同一时钟周期内,对不同的列数据执行相同的指令, 实际上执行吞吐量(throughput of execution)可以提高 4 倍或更多。列式数据可以遵循 SIMD 处理,这样可以存储列值到内存中的有序排列且字节对齐的密集数组中,这些数据会载入到固定宽度的 SIMD 寄存器中。现在的 Intel 编译器配置了 AVX-512(高级矢量扩展)指令集,该指令集增加 SIMD 寄存器的宽度到 512 比特。换而言之,可以并行运算 16 个 4 字节的整数列值。其它的 SIMD 指令集还有 SSE,SSE2,AVX,AVX2。
# 总结
- 向量模型相比传统模型大大减少了函数的调用数量
- 以块为处理单位数据,提供了 cache 命中率
- 同时处理多行数据,使 SIMD 有了用武之地